El codi Python es:
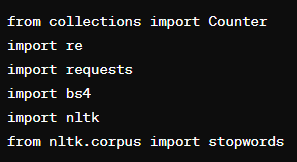
Es importa varies biblioteques amb diferents coses.

Funció principal de main()
Aqui teniu el codi Python complet
"""
Gensim 4.0, released March 25, 2021, dropped the Summarization module.
To run this program install Gensim 3.8.3 (https://pypi.org/project/gensim/3.8.3/)
"""
from collections import Counter
import re
import requests
import bs4
import nltk
from nltk.corpus import stopwords
def main():
# Use webscraping to obtain the text.
url = 'https://dyang.neocities.org/chapter3/dream.html'
page = requests.get(url)
page.raise_for_status()
soup = bs4.BeautifulSoup(page.text, 'html.parser')
p_elems = [element.text for element in soup.find_all('p')]
speech = ' '.join(p_elems) # Make sure to join on a space!
# Fix typos, remove extra spaces, digits, and punctuation.
speech = speech.replace(')mowing', 'knowing')
speech = re.sub('\s+', ' ', speech)
speech_edit = re.sub('[^a-zA-Z]', ' ', speech)
speech_edit = re.sub('\s+', ' ', speech_edit)
# Request input.
while True:
max_words = input("Enter max words per sentence for summary: ")
num_sents = input("Enter number of sentences for summary: ")
if max_words.isdigit() and num_sents.isdigit():
break
else:
print("\nInput must be in whole numbers.\n")
# Run functions to generate sentence scores.
speech_edit_no_stop = remove_stop_words(speech_edit)
word_freq = get_word_freq(speech_edit_no_stop)
sent_scores = score_sentences(speech, word_freq, max_words)
# Print the top-ranked sentences.
counts = Counter(sent_scores)
summary = counts.most_common(int(num_sents))
print("\nSUMMARY:")
for i in summary:
print(i[0])
def remove_stop_words(speech_edit):
"""Remove stop words from string and return string."""
stop_words = set(stopwords.words('english'))
speech_edit_no_stop = ''
for word in nltk.word_tokenize(speech_edit):
if word.lower() not in stop_words:
speech_edit_no_stop += word + ' '
return speech_edit_no_stop
def get_word_freq(speech_edit_no_stop):
"""Return a dictionary of word frequency in a string."""
word_freq = nltk.FreqDist(nltk.word_tokenize(speech_edit_no_stop.lower()))
return word_freq
def score_sentences(speech, word_freq, max_words):
"""Return dictionary of sentence scores based on word frequency."""
sent_scores = dict()
sentences = nltk.sent_tokenize(speech)
for sent in sentences:
sent_scores[sent] = 0
words = nltk.word_tokenize(sent.lower())
sent_word_count = len(words)
if sent_word_count <= int(max_words):
for word in words:
if word in word_freq.keys():
sent_scores[sent] += word_freq[word]
sent_scores[sent] = sent_scores[sent] / sent_word_count
return sent_scores
if __name__ == '__main__':
main()